PROTOCOLO HTTP
Hypertext Transfer Protocol
From Wikipedia, the free encyclopedia

| Internet protocol suite |
|---|
| Application layer |
| Transport layer |
| Internet layer |
| Link layer |
Hypertext is structured text that uses logical links (hyperlinks) between nodes containing text. HTTP is the protocol to exchange or transfer hypertext.
The standards development of HTTP was coordinated by the Internet Engineering Task Force (IETF) and the World Wide Web Consortium (W3C), culminating in the publication of a series of Requests for Comments (RFCs), most notably RFC 2616 (June 1999), which defines HTTP/1.1, the version of HTTP in common use.
Contents
Technical overview
HTTP functions as a request-response protocol in the client-server computing model. A web browser, for example, may be the client and an application running on a computer hosting a web site may be the server. The client submits an HTTP request message to the server. The server, which provides resources such as HTML files and other content, or performs other functions on behalf of the client, returns a response message to the client. The response contains completion status information about the request and may also contain requested content in its message body.
A web browser is an example of a user agent (UA). Other types of user agent include the indexing software used by search providers (web crawlers), voice browsers, mobile apps and other software that accesses, consumes or displays web content.
HTTP is designed to permit intermediate network elements to improve or enable communications between clients and servers. High-traffic websites often benefit from web cache servers that deliver content on behalf of upstream servers to improve response time. Web browsers cache previously accessed web resources and reuse them when possible to reduce network traffic. HTTP proxy servers at private network boundaries can facilitate communication for clients without a globally routable address, by relaying messages with external servers.
HTTP is an application layer protocol designed within the framework of the Internet Protocol Suite. Its definition presumes an underlying and reliable transport layer protocol,[2] and Transmission Control Protocol (TCP) is commonly used. However HTTP can use unreliable protocols such as the User Datagram Protocol (UDP), for example in Simple Service Discovery Protocol (SSDP).
HTTP resources are identified and located on the network by Uniform Resource Identifiers (URIs)—or, more specifically, Uniform Resource Locators (URLs)—using the http or https URI schemes. URIs and hyperlinks in Hypertext Markup Language (HTML) documents form webs of inter-linked hypertext documents.
HTTP/1.1 is a revision of the original HTTP (HTTP/1.0). In HTTP/1.0 a separate connection to the same server is made for every resource request. HTTP/1.1 can reuse a connection multiple times to download images, scripts, stylesheets et cetera after the page has been delivered. HTTP/1.1 communications therefore experience less latency as the establishment of TCP connections presents considerable overhead.
History
The term HyperText was coined by Ted Nelson who in turn was inspired by Vannevar Bush's microfilm-based "memex". Tim Berners-Lee first proposed the "WorldWideWeb" project — now known as the World Wide Web. Berners-Lee and his team are credited with inventing the original HTTP along with HTML and the associated technology for a web server and a text-based web browser. The first version of the protocol had only one method, namely GET, which would request a page from a server.[3] The response from the server was always an HTML page.[4]
The first documented version of HTTP was HTTP V0.9 (1991). Dave Raggett led the HTTP Working Group (HTTP WG) in 1995 and wanted to expand the protocol with extended operations, extended negotiation, richer meta-information, tied with a security protocol which became more efficient by adding additional methods and header fields.[5][6] RFC 1945 officially introduced and recognized HTTP V1.0 in 1996.
The HTTP WG planned to publish new standards in December 1995[7] and the support for pre-standard HTTP/1.1 based on the then developing RFC 2068 (called HTTP-NG) was rapidly adopted by the major browser developers in early 1996. By March 1996, pre-standard HTTP/1.1 was supported in Arena,[8] Netscape 2.0,[8] Netscape Navigator Gold 2.01,[8] Mosaic 2.7,[citation needed] Lynx 2.5[citation needed], and in Internet Explorer 2.0[citation needed]. End-user adoption of the new browsers was rapid. In March 1996, one web hosting company reported that over 40% of browsers in use on the Internet were HTTP 1.1 compliant.[citation needed] That same web hosting company reported that by June 1996, 65% of all browsers accessing their servers were HTTP/1.1 compliant.[9] The HTTP/1.1 standard as defined in RFC 2068 was officially released in January 1997. Improvements and updates to the HTTP/1.1 standard were released under RFC 2616 in June 1999.
HTTP session
An HTTP session is a sequence of network request-response transactions. An HTTP client initiates a request by establishing a Transmission Control Protocol (TCP) connection to a particular port on a server (typically port 80; see List of TCP and UDP port numbers). An HTTP server listening on that port waits for a client's request message. Upon receiving the request, the server sends back a status line, such as "HTTP/1.1 200 OK", and a message of its own. The body of this message is typically the requested resource, although an error message or other information may also be returned.[1]Request methods

The HTTP/1.0 specification[10]:section 8 defined the GET, POST and HEAD methods and the HTTP/1.1 specification[1]:section 9 added 5 new methods: OPTIONS, PUT, DELETE, TRACE and CONNECT. By being specified in these documents their semantics are well known and can be depended upon. Any client can use any method and the server can be configured to support any combination of methods. If a method is unknown to an intermediate it will be treated as an unsafe and non-idempotent method. There is no limit to the number of methods that can be defined and this allows for future methods to be specified without breaking existing infrastructure. For example WebDAV defined 7 new methods and RFC5789 specified the PATCH method.
- GET
- Requests a representation of the specified resource. Requests using GET should only retrieve data and should have no other effect. (This is also true of some other HTTP methods.)[1] The W3C has published guidance principles on this distinction, saying, "Web application design should be informed by the above principles, but also by the relevant limitations."[11] See safe methods below.
- HEAD
- Asks for the response identical to the one that would correspond to a GET request, but without the response body. This is useful for retrieving meta-information written in response headers, without having to transport the entire content.
- POST
- Requests that the server accept the entity enclosed in the request as a new subordinate of the web resource identified by the URI. The data POSTed might be, as examples, an annotation for existing resources; a message for a bulletin board, newsgroup, mailing list, or comment thread; a block of data that is the result of submitting a web form to a data-handling process; or an item to add to a database.[12]
- PUT
- Requests that the enclosed entity be stored under the supplied URI. If the URI refers to an already existing resource, it is modified; if the URI does not point to an existing resource, then the server can create the resource with that URI.[13]
- DELETE
- Deletes the specified resource.
- TRACE
- Echoes back the received request so that a client can see what (if any) changes or additions have been made by intermediate servers.
- OPTIONS
- Returns the HTTP methods that the server supports for the specified URL. This can be used to check the functionality of a web server by requesting '*' instead of a specific resource.
- CONNECT
- Converts the request connection to a transparent TCP/IP tunnel, usually to facilitate SSL-encrypted communication (HTTPS) through an unencrypted HTTP proxy.[14][15]
- PATCH
- Is used to apply partial modifications to a resource.[16]
Safe methods
Some methods (for example, HEAD, GET, OPTIONS and TRACE) are defined as safe, which means they are intended only for information retrieval and should not change the state of the server. In other words, they should not have side effects, beyond relatively harmless effects such as logging, caching, the serving of banner advertisements or incrementing a web counter. Making arbitrary GET requests without regard to the context of the application's state should therefore be considered safe.By contrast, methods such as POST, PUT and DELETE are intended for actions that may cause side effects either on the server, or external side effects such as financial transactions or transmission of email. Such methods are therefore not usually used by conforming web robots or web crawlers; some that do not conform tend to make requests without regard to context or consequences.
Despite the prescribed safety of GET requests, in practice their handling by the server is not technically limited in any way. Therefore, careless or deliberate programming can cause non-trivial changes on the server. This is discouraged, because it can cause problems for Web caching, search engines and other automated agents, which can make unintended changes on the server.
Idempotent methods and web applications
Methods PUT and DELETE are defined to be idempotent, meaning that multiple identical requests should have the same effect as a single request (Note that idempotence refers to the state of the system after the request has completed, so while the action the server takes (e.g. deleting a record) or the response code it returns may be different on subsequent requests, the system state will be the same every time). Methods GET, HEAD, OPTIONS and TRACE, being prescribed as safe, should also be idempotent, as HTTP is a stateless protocol.[1]In contrast, the POST method is not necessarily idempotent, and therefore sending an identical POST request multiple times may further affect state or cause further side effects (such as financial transactions). In some cases this may be desirable, but in other cases this could be due to an accident, such as when a user does not realize that their action will result in sending another request, or they did not receive adequate feedback that their first request was successful. While web browsers may show alert dialog boxes to warn users in some cases where reloading a page may re-submit a POST request, it is generally up to the web application to handle cases where a POST request should not be submitted more than once.
Note that whether a method is idempotent is not enforced by the protocol or web server. It is perfectly possible to write a web application in which (for example) a database insert or other non-idempotent action is triggered by a GET or other request. Ignoring this recommendation, however, may result in undesirable consequences, if a user agent assumes that repeating the same request is safe when it isn't.
Security
Implementing methods such as TRACE, TRACK and DEBUG are considered potentially insecure by some security professionals because attackers can use them to gather information or bypass security controls during attacks. Security software tools such as Tenable Nessus and Microsoft UrlScan Security Tool report on the presence of these methods as being security issues.[18]TRACK and DEBUG are not valid HTTP 1.1 verbs.[19]
Status codes
See also: List of HTTP status codes
In HTTP/1.0 and since, the first line of the HTTP response is called the status line and includes a numeric status code (such as "404") and a textual reason phrase (such as "Not Found"). The way the user agent handles the response primarily depends on the code and secondarily on the response headers.
Custom status codes can be used since, if the user agent encounters a
code it does not recognize, it can use the first digit of the code to
determine the general class of the response.[20]Also, the standard reason phrases are only recommendations and can be replaced with "local equivalents" at the web developer's discretion. If the status code indicated a problem, the user agent might display the reason phrase to the user to provide further information about the nature of the problem. The standard also allows the user agent to attempt to interpret the reason phrase, though this might be unwise since the standard explicitly specifies that status codes are machine-readable and reason phrases are human-readable.
Persistent connections
Main article: HTTP persistent connection
In HTTP/0.9 and 1.0, the connection is closed after a single
request/response pair. In HTTP/1.1 a keep-alive-mechanism was
introduced, where a connection could be reused for more than one
request. Such persistent connections reduce request latency
perceptibly, because the client does not need to re-negotiate the TCP
3-Way-Handshake connection after the first request has been sent.
Another positive side effect is that in general the connection becomes
faster with time due to TCP's slow-start-mechanism.Version 1.1 of the protocol also made bandwidth optimization improvements to HTTP/1.0. For example, HTTP/1.1 introduced chunked transfer encoding to allow content on persistent connections to be streamed rather than buffered. HTTP pipelining further reduces lag time, allowing clients to send multiple requests before waiting for each response. Another improvement to the protocol was byte serving, where a server transmits just the portion of a resource explicitly requested by a client.
HTTP session state
HTTP is a stateless protocol. A stateless protocol does not require the HTTP server to retain information or status about each user for the duration of multiple requests. However, some web applications implement states or server side sessions using one or more of the following methods:- Hidden variables within web forms.
- HTTP cookies.
- Query string parameters, for example, /index.php?session_id=some_unique_session_code.
Encrypted connections
The most popular way of establishing an encrypted HTTP connection is HTTP Secure.Two other methods for establishing an encrypted HTTP connection also exist, called Secure Hypertext Transfer Protocol and the HTTP/1.1 Upgrade header. Browser support, for these latter two, is, however, nearly non-existent,[citation needed] so HTTP Secure is the dominant method of establishing an encrypted HTTP connection.
Request message
The request message consists of the following:- A request line, for example GET /images/logo.png HTTP/1.1, which requests a resource called /images/logo.png from the server.
- Request Headers, such as Accept-Language: en
- An empty line.
- An optional message body.
A request line containing only the path name is accepted by servers to maintain compatibility with HTTP clients before the HTTP/1.0 specification in RFC 1945.[22]
Response message
The response message consists of the following:- A Status-Line (for example HTTP/1.1 200 OK, which indicates that the client's request succeeded)
- Response Headers, such as Content-Type: text/html
- An empty line
- An optional message body
Example session
Below is a sample conversation between an HTTP client and an HTTP server running on www.example.com, port 80.Client request
GET /index.html HTTP/1.1 Host: www.example.comA client request (consisting in this case of the request line and only one header) is followed by a blank line, so that the request ends with a double newline, each in the form of a carriage return followed by a line feed. The "Host" header distinguishes between various DNS names sharing a single IP address, allowing name-based virtual hosting. While optional in HTTP/1.0, it is mandatory in HTTP/1.1.
Server response
HTTP/1.1 200 OK Date: Mon, 23 May 2005 22:38:34 GMT Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux) Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT ETag: "3f80f-1b6-3e1cb03b" Content-Type: text/html; charset=UTF-8 Content-Length: 131 Connection: close <html> <head> <title>An Example Page</title> </head> <body> Hello World, this is a very simple HTML document. </body> </html>The ETag (entity tag) header is used to determine if a cached version of the requested resource is identical to the current version of the resource on the server. Content-Type specifies the Internet media type of the data conveyed by the HTTP message, while Content-Length indicates its length in bytes. The HTTP/1.1 webserver publishes its ability to respond to requests for certain byte ranges of the document by setting the header Accept-Ranges: bytes. This is useful, if the client needs to have only certain portions[23] of a resource sent by the server, which is called byte serving. When Connection: close is sent in a header, it means that the web server will close the TCP connection immediately after the transfer of this response.
Most of the header lines are optional. When Content-Length is missing the length is determined in other ways. Chunked transfer encoding uses a chunk size of 0 to mark the end of the content. Identity encoding without Content-Length reads content until the socket is closed.
A Content-Encoding like gzip can be used to compress the transmitted data.
List of HTTP status codes
From Wikipedia, the free encyclopedia
| HTTP |
|---|
| Request methods |
| Header fields |
| Status codes |
The Internet Assigned Numbers Authority (IANA) maintains the official registry of HTTP status codes.
Microsoft IIS sometimes uses additional decimal sub-codes to provide more specific information,[1] but these are not listed here.
Contents
1xx Informational
Request received, continuing process.[2]This class of status code indicates a provisional response, consisting only of the Status-Line and optional headers, and is terminated by an empty line. Since HTTP/1.0 did not define any 1xx status codes, servers must not send a 1xx response to an HTTP/1.0 client except under experimental conditions.
- 100 Continue
- This means that the server has received the request headers, and
that the client should proceed to send the request body (in the case of a
request for which a body needs to be sent; for example, a POST
request). If the request body is large, sending it to a server when a
request has already been rejected based upon inappropriate headers is
inefficient. To have a server check if the request could be accepted
based on the request's headers alone, a client must send
Expect: 100-continueas a header in its initial request[2] and check if a100 Continuestatus code is received in response before continuing (or receive417 Expectation Failedand not continue).[2] - 101 Switching Protocols
- This means the requester has asked the server to switch protocols and the server is acknowledging that it will do so.[2]
- 102 Processing (WebDAV; RFC 2518)
- As a WebDAV request may contain many sub-requests involving file operations, it may take a long time to complete the request. This code indicates that the server has received and is processing the request, but no response is available yet.[3] This prevents the client from timing out and assuming the request was lost.
2xx Success
This class of status codes indicates the action requested by the client was received, understood, accepted and processed successfully.- 200 OK
- Standard response for successful HTTP requests. The actual response will depend on the request method used. In a GET request, the response will contain an entity corresponding to the requested resource. In a POST request the response will contain an entity describing or containing the result of the action.[2]
- 201 Created
- The request has been fulfilled and resulted in a new resource being created.[2]
- 202 Accepted
- The request has been accepted for processing, but the processing has not been completed. The request might or might not eventually be acted upon, as it might be disallowed when processing actually takes place.[2]
- 203 Non-Authoritative Information (since HTTP/1.1)
- The server successfully processed the request, but is returning information that may be from another source.[2]
- 204 No Content
- The server successfully processed the request, but is not returning any content.[2] Usually used as a response to a successful delete request.
- 205 Reset Content
- The server successfully processed the request, but is not returning any content. Unlike a 204 response, this response requires that the requester reset the document view.[2]
- 206 Partial Content
- The server is delivering only part of the resource due to a range header sent by the client. The range header is used by tools like wget to enable resuming of interrupted downloads, or split a download into multiple simultaneous streams.[2]
- 207 Multi-Status (WebDAV; RFC 4918)
- The message body that follows is an XML message and can contain a number of separate response codes, depending on how many sub-requests were made.[4]
- 208 Already Reported (WebDAV; RFC 5842)
- The members of a DAV binding have already been enumerated in a previous reply to this request, and are not being included again.
- 226 IM Used (RFC 3229)
- The server has fulfilled a GET request for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance.[5]
3xx Redirection
The client must take additional action to complete the request.[2]This class of status code indicates that further action needs to be taken by the user agent to fulfil the request. The action required may be carried out by the user agent without interaction with the user if and only if the method used in the second request is GET or HEAD. A user agent should not automatically redirect a request more than five times, since such redirections usually indicate an infinite loop.
- 300 Multiple Choices
- Indicates multiple options for the resource that the client may follow. It, for instance, could be used to present different format options for video, list files with different extensions, or word sense disambiguation.[2]
- 301 Moved Permanently
- This and all future requests should be directed to the given URI.[2]
- 302 Found
- This is an example of industry practice contradicting the standard.[2] The HTTP/1.0 specification (RFC 1945) required the client to perform a temporary redirect (the original describing phrase was "Moved Temporarily"),[6] but popular browsers implemented 302 with the functionality of a 303 See Other. Therefore, HTTP/1.1 added status codes 303 and 307 to distinguish between the two behaviours.[7] However, some Web applications and frameworks use the 302 status code as if it were the 303.[8]
- 303 See Other (since HTTP/1.1)
- The response to the request can be found under another URI using a GET method. When received in response to a POST (or PUT/DELETE), it should be assumed that the server has received the data and the redirect should be issued with a separate GET message.[2]
- 304 Not Modified
- Indicates that the resource has not been modified since the version specified by the request headers If-Modified-Since or If-Match.[2] This means that there is no need to retransmit the resource, since the client still has a previously-downloaded copy.
- 305 Use Proxy (since HTTP/1.1)
- The requested resource is only available through a proxy, whose address is provided in the response.[2] Many HTTP clients (such as Mozilla[9] and Internet Explorer) do not correctly handle responses with this status code, primarily for security reasons.[citation needed]
- 306 Switch Proxy
- No longer used.[2] Originally meant "Subsequent requests should use the specified proxy."[10]
- 307 Temporary Redirect (since HTTP/1.1)
- In this case, the request should be repeated with another URI; however, future requests should still use the original URI.[2] In contrast to how 302 was historically implemented, the request method is not allowed to be changed when reissuing the original request. For instance, a POST request should be repeated using another POST request.[11]
- 308 Permanent Redirect (approved as experimental RFC)[12]
- The request, and all future requests should be repeated using another URI. 307 and 308 (as proposed) parallel the behaviours of 302 and 301, but do not allow the HTTP method to change. So, for example, submitting a form to a permanently redirected resource may continue smoothly.
4xx Client Error
The 4xx class of status code is intended for cases in which the client seems to have erred. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and whether it is a temporary or permanent condition. These status codes are applicable to any request method. User agents should display any included entity to the user.- 400 Bad Request
- The request cannot be fulfilled due to bad syntax.[2]
- 401 Unauthorized
- Similar to 403 Forbidden, but specifically for use when authentication is required and has failed or has not yet been provided.[2] The response must include a WWW-Authenticate header field containing a challenge applicable to the requested resource. See Basic access authentication and Digest access authentication.
- 402 Payment Required
- Reserved for future use.[2] The original intention was that this code might be used as part of some form of digital cash or micropayment scheme, but that has not happened, and this code is not usually used. As an example of its use, however, Apple's defunct MobileMe service generated a 402 error if the MobileMe account was delinquent.[citation needed] In addition, YouTube uses this status if a particular IP address has made excessive requests, and requires the person to enter a CAPTCHA.
- 403 Forbidden
- The request was a valid request, but the server is refusing to respond to it.[2] Unlike a 401 Unauthorized response, authenticating will make no difference.[2] On servers where authentication is required, this commonly means that the provided credentials were successfully authenticated but that the credentials still do not grant the client permission to access the resource (e.g., a recognized user attempting to access restricted content).
- 404 Not Found
- The requested resource could not be found but may be available again in the future.[2] Subsequent requests by the client are permissible.
- 405 Method Not Allowed
- A request was made of a resource using a request method not supported by that resource;[2] for example, using GET on a form which requires data to be presented via POST, or using PUT on a read-only resource.
- 406 Not Acceptable
- The requested resource is only capable of generating content not acceptable according to the Accept headers sent in the request.[2]
- 407 Proxy Authentication Required
- The client must first authenticate itself with the proxy.[2]
- 408 Request Timeout
- The server timed out waiting for the request.[2] According to W3 HTTP specifications: "The client did not produce a request within the time that the server was prepared to wait. The client MAY repeat the request without modifications at any later time."
- 409 Conflict
- Indicates that the request could not be processed because of conflict in the request, such as an edit conflict in the case of multiple updates.[2]
- 410 Gone
- Indicates that the resource requested is no longer available and will not be available again.[2] This should be used when a resource has been intentionally removed and the resource should be purged. Upon receiving a 410 status code, the client should not request the resource again in the future. Clients such as search engines should remove the resource from their indices. Most use cases do not require clients and search engines to purge the resource, and a "404 Not Found" may be used instead.
- 411 Length Required
- The request did not specify the length of its content, which is required by the requested resource.[2]
- 412 Precondition Failed
- The server does not meet one of the preconditions that the requester put on the request.[2]
- 413 Request Entity Too Large
- The request is larger than the server is willing or able to process.[2]
- 414 Request-URI Too Long
- The URI provided was too long for the server to process.[2] Often the result of too much data being encoded as a query-string of a GET request, in which case it should be converted to a POST request.
- 415 Unsupported Media Type
- The request entity has a media type which the server or resource does not support.[2] For example, the client uploads an image as image/svg+xml, but the server requires that images use a different format.
- 416 Requested Range Not Satisfiable
- The client has asked for a portion of the file, but the server cannot supply that portion.[2] For example, if the client asked for a part of the file that lies beyond the end of the file.[2]
- 417 Expectation Failed
- The server cannot meet the requirements of the Expect request-header field.[2]
- 418 I'm a teapot (RFC 2324)
- This code was defined in 1998 as one of the traditional IETF April Fools' jokes, in RFC 2324, Hyper Text Coffee Pot Control Protocol, and is not expected to be implemented by actual HTTP servers.
- 419 Authentication Timeout (not in RFC 2616)
- Not a part of the HTTP standard, 419 Authentication Timeout denotes that previously valid authentication has expired. It is used as an alternative to 401 Unauthorized in order to differentiate from otherwise authenticated clients being denied access to specific server resources[citation needed].
- 420 Method Failure (Spring Framework)
- Not part of the HTTP standard, but defined by Spring in the HttpStatus class to be used when a method failed. This status code is deprecated by Spring.
- 420 Enhance Your Calm (Twitter)
- Not part of the HTTP standard, but returned by the Twitter Search and Trends API when the client is being rate limited.[13] Other services may wish to implement the 429 Too Many Requests response code instead.
- 422 Unprocessable Entity (WebDAV; RFC 4918)
- The request was well-formed but was unable to be followed due to semantic errors.[4]
- 423 Locked (WebDAV; RFC 4918)
- The resource that is being accessed is locked.[4]
- 424 Failed Dependency (WebDAV; RFC 4918)
- The request failed due to failure of a previous request (e.g., a PROPPATCH).[4]
- 424 Method Failure (WebDAV)[14]
- Indicates the method was not executed on a particular resource within its scope because some part of the method's execution failed causing the entire method to be aborted.
- 425 Unordered Collection (Internet draft)
- Defined in drafts of "WebDAV Advanced Collections Protocol",[15] but not present in "Web Distributed Authoring and Versioning (WebDAV) Ordered Collections Protocol".[16]
- 426 Upgrade Required (RFC 2817)
- The client should switch to a different protocol such as TLS/1.0.[17]
- 428 Precondition Required (RFC 6585)
- The origin server requires the request to be conditional. Intended to prevent "the 'lost update' problem, where a client GETs a resource's state, modifies it, and PUTs it back to the server, when meanwhile a third party has modified the state on the server, leading to a conflict."[18]
- 429 Too Many Requests (RFC 6585)
- The user has sent too many requests in a given amount of time. Intended for use with rate limiting schemes.[18]
- 431 Request Header Fields Too Large (RFC 6585)
- The server is unwilling to process the request because either an individual header field, or all the header fields collectively, are too large.[18]
- 444 No Response (Nginx)
- Used in Nginx logs to indicate that the server has returned no information to the client and closed the connection (useful as a deterrent for malware).
- 449 Retry With (Microsoft)
- A Microsoft extension. The request should be retried after performing the appropriate action.[19]
- Often search-engines or custom applications will ignore required parameters. Where no default action is appropriate, the Aviongoo website sends a "HTTP/1.1 449 Retry with valid parameters: param1, param2, . . ." response. The applications may choose to learn, or not.
- 450 Blocked by Windows Parental Controls (Microsoft)
- A Microsoft extension. This error is given when Windows Parental Controls are turned on and are blocking access to the given webpage.[20]
- 451 Unavailable For Legal Reasons (Internet draft)
- Defined in the internet draft "A New HTTP Status Code for Legally-restricted Resources".[21] Intended to be used when resource access is denied for legal reasons, e.g. censorship or government-mandated blocked access. A reference to the 1953 dystopian novel Fahrenheit 451, where books are outlawed.[22]
- 451 Redirect (Microsoft)
- Used in Exchange ActiveSync if there either is a more efficient server to use or the server can't access the users' mailbox.[23]
- The client is supposed to re-run the HTTP Autodiscovery protocol to find a better suited server.[24]
- 494 Request Header Too Large (Nginx)
- Nginx internal code similar to 431 but it was introduced earlier.[25][original research?]
- 495 Cert Error (Nginx)
- Nginx internal code used when SSL client certificate error occurred to distinguish it from 4XX in a log and an error page redirection.
- 496 No Cert (Nginx)
- Nginx internal code used when client didn't provide certificate to distinguish it from 4XX in a log and an error page redirection.
- 497 HTTP to HTTPS (Nginx)
- Nginx internal code used for the plain HTTP requests that are sent to HTTPS port to distinguish it from 4XX in a log and an error page redirection.
- 499 Client Closed Request (Nginx)
- Used in Nginx logs to indicate when the connection has been closed by client while the server is still processing its request, making server unable to send a status code back.[26]
5xx Server Error
The server failed to fulfill an apparently valid request.[2]Response status codes beginning with the digit "5" indicate cases in which the server is aware that it has encountered an error or is otherwise incapable of performing the request. Except when responding to a HEAD request, the server should include an entity containing an explanation of the error situation, and indicate whether it is a temporary or permanent condition. Likewise, user agents should display any included entity to the user. These response codes are applicable to any request method.
- 500 Internal Server Error
- A generic error message, given when no more specific message is suitable.[2]
- 501 Not Implemented
- The server either does not recognize the request method, or it lacks the ability to fulfill the request.[2] Usually this implies future availability (e.g., a new feature of a web-service API).
- 502 Bad Gateway
- The server was acting as a gateway or proxy and received an invalid response from the upstream server.[2]
- 503 Service Unavailable
- The server is currently unavailable (because it is overloaded or down for maintenance).[2] Generally, this is a temporary state. Sometimes, this can be permanent as well on test servers.
- 504 Gateway Timeout
- The server was acting as a gateway or proxy and did not receive a timely response from the upstream server.[2]
- 505 HTTP Version Not Supported
- The server does not support the HTTP protocol version used in the request.[2]
- 506 Variant Also Negotiates (RFC 2295)
- Transparent content negotiation for the request results in a circular reference.[27]
- 507 Insufficient Storage (WebDAV; RFC 4918)
- The server is unable to store the representation needed to complete the request.[4]
- 508 Loop Detected (WebDAV; RFC 5842)
- The server detected an infinite loop while processing the request (sent in lieu of 208 Not Reported).
- 509 Bandwidth Limit Exceeded (Apache bw/limited extension)
- This status code, while used by many servers, is not specified in any RFCs.
- 510 Not Extended (RFC 2774)
- Further extensions to the request are required for the server to fulfill it.[28]
- 511 Network Authentication Required (RFC 6585)
- The client needs to authenticate to gain network access. Intended for use by intercepting proxies used to control access to the network (e.g., "captive portals" used to require agreement to Terms of Service before granting full Internet access via a Wi-Fi hotspot).[18]
- 522 Connection timed out
- The server connection timed out.
- 524 A timeout occurred
- This status code is not specified in any RFCs, but is used by Cloudflare's reverse proxies to signal a network read timeout behind the proxy to a client in front of the proxy.
- 598 Network read timeout error (Unknown)
- This status code is not specified in any RFCs, but is used by Microsoft HTTP proxies to signal a network read timeout behind the proxy to a client in front of the proxy.[citation needed]
- 599 Network connect timeout error (Unknown)
- This status code is not specified in any RFCs, but is used by Microsoft HTTP proxies to signal a network connect timeout behind the proxy to a client in front of the proxy.[citation needed]
HTTP 302
From Wikipedia, the free encyclopedia
The HTTP response status code 302 Found is a common way of performing a redirection.HTTP Request methods Header fields Status codes
An HTTP response with this status code will additionally provide a URL in the Location header field. The User Agent (e.g. a web browser) is invited by a response with this code to make a second, otherwise identical, request, to the new URL specified in the Location field. The HTTP/1.0 specification (RFC 1945) defines this code, and gives it the description phrase "Moved Temporarily".
Many web browsers implemented this code in a manner that violated this standard, changing the request type of the new request to GET, regardless of the type employed in the original request (e.g. POST).[1] For this reason, HTTP/1.1 (RFC 2616) added the new status codes 303 and 307 to disambiguate between the two behaviours, with 303 mandating the change of request type to GET, and 307 preserving the request type as originally sent. Despite the greater clarity provided by this disambiguation, the 302 code is still employed in web frameworks to preserve compatibility with browsers that do not implement the HTTP/1.1 specification.[2]
Contents
Example
Client request:
GET /index.html HTTP/1.1 Host: www.example.com
Server response:
HTTP/1.1 302 Location: http://www.iana.org/domains/example/
Apache HTTP Server
From Wikipedia, the free encyclopedia
The Apache HTTP Server, commonly referred to as Apache (/əˈpætʃiː/ ə-PA-chee), is a web server application notable for playing a key role in the initial growth of the World Wide Web.[3] Originally based on the NCSA HTTPd server, development of Apache began in early 1995 after work on the NCSA code stalled. Apache quickly overtook NCSA HTTPd as the dominant HTTP server, and has remained the most popular HTTP server in use since April 1996. In 2009, it became the first web server software to serve more than 100 million websites.[4]Apache HTTP Server 
Original author(s) Robert McCool Developer(s) Apache Software Foundation Initial release 1995[1] Stable release 2.4.6 (July 22, 2013) [±]
Development status Active Written in C[2] Operating system Cross-platform Available in English Type Web server License Apache License 2.0 Website httpd.apache.org
Apache is developed and maintained by an open community of developers under the auspices of the Apache Software Foundation. Most commonly used on a Unix-like system,[5] the software is available for a wide variety of operating systems, including Unix, FreeBSD, Linux, Solaris, Novell NetWare, OS X, Microsoft Windows, OS/2, TPF, and eComStation. Released under the Apache License, Apache is open-source software.
As of June 2013, Apache was estimated to serve 54.2% of all active websites and 53.3% of the top servers across all domains.[6][7][8][9][10]
Contents
Name
According to the FAQ in the Apache project website, the name Apache was chosen out of respect to the Native American tribe Apache and its superior skills in warfare and strategy. The name was widely believed to be a pun on A Patchy Server (since it was a set of software patches), but this is erroneous.[11] Official documentation used to give this very explanation of the name,[12] but in a 2000 interview, Brian Behlendorf, one of the creators of Apache, set the record straight:
The name literally came out of the blue. I wish I could say that it was something fantastic, but it was out of the blue. I put it on a page and then a few months later when this project started, I pointed people to this page and said: "Hey, what do you think of that idea?" ... Someone said they liked the name and that it was a really good pun. And I was like, "A pun? What do you mean?" He said, "Well, we're building a server out of a bunch of software patches, right? So it's a patchy Web server." I went, "Oh, all right." ... When I thought of the name, no. It just sort of connoted: "Take no prisoners. Be kind of aggressive and kick some ass."
—Brian Behlendorf, [13]Features
Apache supports a variety of features, many implemented as compiled modules which extend the core functionality. These can range from server-side programming language support to authentication schemes. Some common language interfaces support Perl, Python, Tcl, and PHP. Popular authentication modules include mod_access, mod_auth, mod_digest, and mod_auth_digest, the successor to mod_digest. A sample of other features include Secure Sockets Layer and Transport Layer Security support (mod_ssl), a proxy module (mod_proxy), a URL rewriter (mod_rewrite), custom log files (mod_log_config), and filtering support (mod_include and mod_ext_filter).
Popular compression methods on Apache include the external extension module, mod_gzip, implemented to help with reduction of the size (weight) of web pages served over HTTP. ModSecurity is an open source intrusion detection and prevention engine for web applications. Apache logs can be analyzed through a web browser using free scripts such as AWStats/W3Perl or Visitors.
Virtual hosting allows one Apache installation to serve many different websites. For example, one machine with one Apache installation could simultaneously serve www.example.com, www.example.org, test47.test-server.example.edu, etc.
Apache features configurable error messages, DBMS-based authentication databases, and content negotiation. It is also supported by several graphical user interfaces (GUIs).
It supports password authentication and digital certificate authentication. Because the source code is freely available, anyone can adapt the server for specific needs, and there is a large public library of Apache add-ons.[14][15]
Performance
Although the main design goal of Apache is not to be the "fastest" web server, Apache does have performance similar to other "high-performance" web servers. Instead of implementing a single architecture, Apache provides a variety of MultiProcessing Modules (MPMs) which allow Apache to run in a process-based, hybrid (process and thread) or event-hybrid mode, to better match the demands of each particular infrastructure. This implies that the choice of correct MPM and the correct configuration is important. Where compromises in performance need to be made, the design of Apache is to reduce latency and increase throughput, relative to simply handling more requests, thus ensuring consistent and reliable processing of requests within reasonable time-frames.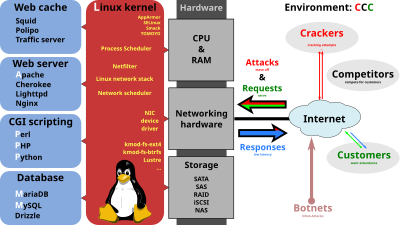 The LAMP software bundle (here additionally with Squid). A high performance and high-availability solution for a hostile environment
The LAMP software bundle (here additionally with Squid). A high performance and high-availability solution for a hostile environment
The Apache 2.2 series was considered significantly slower than nginx for delivering static pages, although remaining significantly faster for dynamic pages. To address this issue, the Apache version considered by the Apache Foundation as providing high-performance is the multi-threaded version which mixes the use of several processes and several threads per process.[16] This architecture, and the way it was implemented in the Apache 2.4 series, provides for performance equivalent or slightly better than event-based webservers.[17]
Licensing
The Apache HTTP Server codebase was relicensed to the Apache 2.0 License (from the previous 1.1 license) in January 2004,[18] and Apache HTTP Server 1.3.31 and 2.0.49 were the first releases using the new license.[19] Some Apache users did not like the change and continued the use of pre-2.0 Apache versions (typically 1.3.x). For example, the OpenBSD project effectively forked Apache 1.3.x for its purposes.[20][21]
Apache HTTP Server Project
The Apache HTTP Server Project is a collaborative software development effort aimed at creating a robust, commercial-grade, feature-rich and freely-available source code implementation of an HTTP (Web) server. The project is jointly managed by a group of volunteers located around the world, using the Internet and the Web to communicate, plan, and develop the server and its related documentation. This project is part of the Apache Software Foundation. In addition, hundreds of users have contributed ideas, code, and documentation to the project.[22][23][List of Apache modules
From Wikipedia, the free encyclopedia-
This list is incomplete; you can help by expanding it.

The following is a list of all the first and third party modules available for the Apache web server:
| Name | Compatibility | Status | Developer(s) | License | Description |
|---|---|---|---|---|---|
| mod_access | Versions older than 2.1 | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Provides access control based on the client and the client's request[1] |
| mod_actions | Versions 1.1 and later | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Provides CGI ability based on request method and media type[2] |
| mod_alias | Versions 1.1 and later | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Allows for client requests to be mapped to different parts of a server's filesystem and for the requests to be redirected entirely[3] |
| mod_asis | Versions 1.3 and later | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Allows for the use of files that contain their own HTTP headers[4] |
| mod_aspdotnet | No longer under the Apache Software Foundation umbrella. Development has been resumed by the original authors at its new home, the mod-aspdotnet SourceForge project. | ||||
| mod_auth | Versions older than 2.1 | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Authenticates users via Basic access authentication by checking against plaintext password and group files. In Apache 2.1 and later, this plaintext authentication is enabled by mod_authn_file instead[5] |
| mod_auth_anon | Versions 1.1-2.1 | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Allows authentication with a special user id of 'anonymous' and an email address as the password. As an authentication mechanism, this was replaced by mod_authn_anon[6] |
| mod_auth_basic | Versions 2.1 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Authenticates users via HTTP Basic Authentication, the backend mechanism for verifying user authentication is left to configurable providers, usually other Apache modules. This module replaces the authentication frontend of several older modules.[7] |
| mod_auth_db | Versions 1.1-1.3 | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Provides user authentication using Berkeley DB files. |
| mod_auth_dbm | Versions older than 2.1 | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | This module provides for HTTP Basic Authentication, where the usernames and passwords are stored in DBM type database files. It is an alternative to the plain text password files provided by mod_auth. |
| mod_auth_digest | Versions 1.3.8 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Authenticates users via HTTP Digest Authentication utilizing MD5 encryption. This is more secure than HTTP Basic Authentication provided by other modules. As of Apache 2.1, this module acts as a front-end to authentication providers who verify the actual login.[8] |
| mod_auth_kerb | |||||
| mod_auth_ldap | Versions 2.0.41-2.1 | Experimental Extension | Apache Software Foundation | Apache License, Version 2.0 | Allows HTTP Basic Authentication by checking against an LDAP directory. The authentication mechanism of checking against an LDAP directory is provided via mod_authnz_ldap in Apache versions 2.1 and later. |
| mod_auth_oid | Version 2.2 | Third-party module | Pascal Buchbinder | GNU General Public License, Version 2 | Allows an Apache server to act as an OpenID "Relying Party"[9] |
| mod_authn_alias | Version 2.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | This module allows extended authentication providers to be created within the configuration file and assigned an alias name. The alias providers can then be referenced through the directives AuthBasicProvider or AuthDigestProvider in the same way as a base authentication provider. |
| mod_authn_anon | Version 2.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Acts as an authentication provider to other modules, like mod_auth_basic and mod_auth_digest, users are authenticated by using a special user id of "anonymous" and providing their email as the password.[10] |
| mod_authn_dbd | Version 2.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | This module provides authentication front-ends such as mod_auth_digest and mod_auth_basic to authenticate users by looking up users in SQL tables. Similar functionality is provided by, for example, mod_authn_file. |
| mod_authn_dbm | Version 2.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | This module provides authentication front-ends such as mod_auth_digest and mod_auth_basic to authenticate users by looking up users in dbm password files. Similar functionality is provided by mod_authn_file. |
| mod_authn_default | Version 2.1 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | This module is designed to be the fallback module, if you don't have configured an authentication module like mod_auth_basic. It simply rejects any credentials supplied by the user. |
| mod_authn_file | Version 2.1 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Acts as an authentication provider to other modules, like mod_auth_basic and mod_auth_digest, by checking users against plaintext password files.[11] |
| mod_authnz_external | |||||
| mod_authnz_ldap | Version 2.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Acts as an authentication provider to other modules and checks authentication against an LDAP directory |
| mod_authnz_mysql | Version 2.2 | This module provides both authentication and authorization for the Apache 2.2 webserver like mod-authnz-ldap . It uses a MySQL database to retrieve user and group informations. | |||
| mod_authz_host | Version 2.1 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Group authorizations based on host (name or IP address) |
| mod_authz_svn | Configuration Directives — Apache configuration directives for configuring path-based authorization for Subversion repositories served through the Apache HTTP Server. | ||||
| mod_autoindex | Version 1.3 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Generates automatic directory listing for display by the server[12] |
| mod_backhand | Seamless redirection of HTTP requests from one web server to another. Can be used to target machines with under-utilized resources. | ||||
| mod_balancer | |||||
| mod_bandwidth | Server-wide or per connection bandwidth limits, based on the directory, size of files and remote IP/domain. | ||||
| mod_bonjour | |||||
| mod_bw | The httpd web server doesn't really have a way to control how much resources a given virtual host can have/ a user can request. This module should be able to limit access to certain areas of the website and to limit malicious users. | ||||
| mod_bwlimited | mod_bwlimited is a CPanel module that allows limiting and monitoring of bandwidth and connection speed etc. It allows CPanel to give very accurate reports of bandwidth usage on HTTP, HTTPS, FTP, SMTP and a few other services as well as limiting bandwidth usage and connection speed. The module is only available on servers running CPanel and isn't available anywhere else | ||||
| mod_c | Third-party module | Cache DLL/SO executables to create very high speed dynamic web pages. mod_c is supported by EHTML (executable HTML) | |||
| mod_cache | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_cern_meta | Version 1.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_cgi | Version 1.1 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_cgid | Version 2.0 and newer, "Unix threaded MPMs only"[13] | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_charset_lite | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_dav | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Provides WebDAV (Web-based Distributed Authoring and Versioning) functionality in Apache. |
| mod_dav_fs | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Acts as a support module for mod_dav and provides access to resources located in the server's file system. |
| mod_define | Version 1.3 and newer | Third Party | Apache License, Version 2.0 | Definition of variables for arbitrary directives. | |
| mod_deflate | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_dir | Version 1.3 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_disk_cache | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_dumpio | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | allows for the logging of all input received by Apache and/or all output sent by Apache to be logged (dumped) to the error.log file. |
| mod_echo | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | This module provides an example protocol module to illustrate the concept. It provides a simple echo server. Telnet to it and type stuff, and it will echo it. |
| mod_env | Version 1.1 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | This module allows for control of internal environment variables that are used by various Apache HTTP Server modules. These variables are also provided to CGI scripts as native system environment variables, and available for use in SSI pages. Environment variables may be passed from the shell which invoked the httpd process. Alternatively, environment variables may be set or unset within the configuration process. |
| mod_evasive | Third-party module | Evasive maneuvers module for Apache to provide evasive action in the event of an HTTP DoS or DDoS attack or brute force attack. Also designed to be a detection and network management tool. | |||
| mod_example | Version 1.2 and newer | Experimental Extension | Apache Software Foundation | Apache License, Version 2.0 | The example module is an actual working module. If you link it into your server, enable the "example-handler" handler for a location, and then browse to that location, you will see a display of some of the tracing the example module did as the various callbacks were made. |
| mod_expires | Version 1.2 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_ext_filter | Version 1.3 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_extract | |||||
| mod_fcgid | Version 2.0, 2.2 and 2.4 | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | mod_fcgid is a high performance alternative to mod_cgi or mod_cgid, which starts a sufficient number instances of the CGI program to handle concurrent requests, and these programs remain running to handle further incoming requests. It is favored by the PHP developers, for example, as a preferred alternative to running mod_php in-process, delivering very similar performance. |
| mod_fastcgi | This 3rd party module provides support for the FastCGI protocol. FastCGI is a language independent, scalable, open extension to CGI that provides high performance and persistence without the limitations of server specific APIs. | ||||
| mod_file_cache | Version 2.0 and newer | Experimental Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_flvx | Stream Flash video | ||||
| mod_frontpage | Starts a service for Microsoft FrontPage. | ||||
| mod_frontpage Mirfak | Apache License, Version 2.0 | Mirfak is an open-source mod_frontpage reimplementation that is more secure, and can be used with a binary installation of Apache (possibly including mod_ssl, php, etc.). The module is licenced under the Apache license. | |||
| mod_geoip | Looks up the IP address of the client end user. Can be used to perform redirection based on country. | ||||
| mod_gnutls | |||||
| mod_gzip | |||||
| mod_headers | Version 1.2 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_h264_streaming | Third-party module | ||||
| mod_ibm_ssl | |||||
| mod_imagemap | |||||
| mod_imap | Version 1.2-2.0 | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_include | Version 1.3 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Enables server-side includes. |
| mod_indent | |||||
| mod_info | Version 1.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_isapi | Version 1.3 and newer, Win32 only | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_jk | Tomcat redirector module. | ||||
| mod_ldap | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_lisp | |||||
| mod_log_config | Version 1.2 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Provides flexible logging of client requests in a customizable format. |
| mod_log_forensic | Version 1.3 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_logio | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Provides the logging of input and output number of bytes received/sent per request. |
| mod_macro | Version 1.3 and newer | Third party | Apache License postcard variant | Allows to define and use macros within Apache runtime configuration files. | |
| mod_magnet | |||||
| mod_mem_cache | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_mime | Version 1.3 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_mime_magic | Version 1.3 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Determines the MIME type of files in the same way the Unix file(1) command works: it looks at the first few bytes of the file. Intended as a "second line of defense" for cases that mod_mime can't resolve. |
| mod_mono | |||||
| mod_musicindex | |||||
| mod_mysql | |||||
| mod_negotiation | Version 1.3 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_nibblebill | |||||
| mod_nss | SSL provider derived from the mod_ssl module for the Apache web server that uses the Network Security Services. | ||||
| mod_ntlm | |||||
| mod_ntlm_winbind | |||||
| mod_ntlm2 | |||||
| mod_nw_ssl | Version 2.0 and newer, Netware only | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_oc4j | |||||
| mod_openpgp | |||||
| mod_ossl | |||||
| mod_owa | |||||
| mod_pagespeed | |||||
| mod_parrot | |||||
| mod_perl | Version 1.3 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Allows usage of Perl within Apache |
| mod_php / libphp5 | Version 1.3 and newer[14] | Third-party module | The PHP Group | PHP License | Enables usage of PHP within Apache |
| mod_psgi | Version 2.2 and newer | Apache License, Version 2.0 | Implements the PSGI specification within Apache | ||
| mod_python | Version 2.0 and newer | Third-party module | Gregory Trubetskoy et al. | Apache License, Version 2.0 | Allows usage of Python within Apache[15] |
| mod_proxy | Version 1.1 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_proxy_connect | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_proxy_ftp | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_proxy_html | Version 2.4 and newer, available as a third-party module for earlier 2.x versions | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Rewrite HTML links in to ensure they are addressable from Clients' networks in a proxy context. |
| mod_proxy_http | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_qos | Version 2.2 | Third-party module | Pascal Buchbinder | GNU General Public License, Version 2 | Controls access to the web server to avoid resource oversubscription. |
| mod_rails | |||||
| mod_rewrite | Version 1.2 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_security | Third-party module | Trustwave SpiderLabs | Apache License, Version 2.0 | Native implementation of the web application firewall, working as an Apache module. Both major Apache branches are supported. | |
| mod_setenvif | Version 1.3 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_setenvifplus | Version 2.2 and newer | Third-party module | Pascal Buchbinder | Apache License, Version 2.0 | Allows Apache to set Environment variables based on different parts of a request parsed by regular expressions[16] |
| mod_so | Version 1.3 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_speling | Version 1.3 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Attempts to correct mistaken URLs that users might have entered by ignoring capitalization and by allowing up to one misspelling |
| mod_ssl | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_sslcrl | Version 2.2 | Third-party module | Pascal Buchbinder | Apache License, Version 2.0 | Verifies the validity of client certificates against Certificate Revocation Lists (CRL) [17] |
| mod_sspi | |||||
| mod_status | Version 1.1 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Provides information on server activity and performance |
| mod_substitute | Version 2.2.7 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Perform search and replace operations on response bodies |
| mod_suexec | Version 2.0 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Allows users to run CGI and SSI applications as a different user |
| mod_suphp | |||||
| mod_throttle | |||||
| mod_tidy | |||||
| mod_tile | |||||
| mod_transform | Filter module that allows Apache to do dynamic XSL Transformations on either static XML documents, or XML documents generated from another Apache module or CGI program. | ||||
| mod_unique_id | Version 1.3 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_upload | |||||
| mod_uploader | |||||
| mod_userdir | Version 1.3 and newer | Included by Default | Apache Software Foundation | Apache License, Version 2.0 | Allows user-specific directories to be accessed using the http://example.com/~user/ syntax. |
| mod_usertrack | Version 1.2 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | |
| mod_version | Version 2.0.56 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Allows version dependent configuration with the container <IfVersion> |
| mod_vhost_alias | Version 1.37 and newer | Stable Extension | Apache Software Foundation | Apache License, Version 2.0 | Creates dynamically configured virtual hosts, by allowing the IP address and/or the Host: header of the HTTP request to be used as part of the pathname to determine what files to serve. |
| mod_virgule | |||||
| mod_vmd | |||||
| mod_wl_20 | |||||
| mod_wl_22 | |||||
| mod_wsgi | |||||
| mod_xsendfile | |||||
| mod_xml2enc | Transcoding module that can be used to extend the internationalisation support of libxml2-based filter modules by converting encoding before and/or after the filter has run. Thus an unsupported input charset can be converted to UTF-8, and output can also be converted to another charset if required. | ||||
| mod_xml | |||||
| mod_xslt | |||||
| mod_xml_curl | |||||
| mod_xmlrpc | |||||
| mod_xrv | |||||
| mod_zlib |
No hay comentarios:
Publicar un comentario